Partially Relevant Video Retrieval
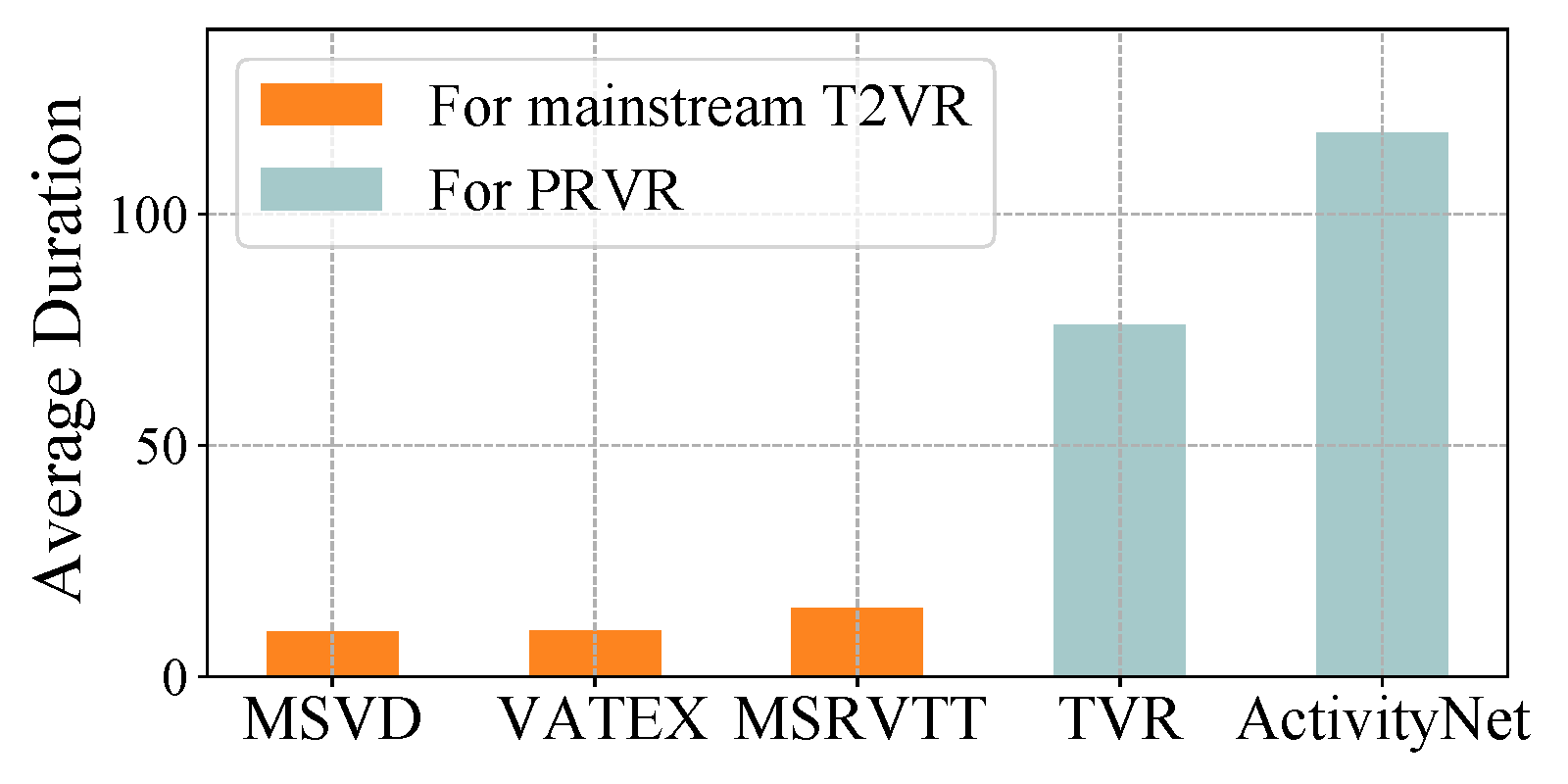
Given a natural language query, the task of PRVR aims to retrieve videos containing a moment that is semantically relevant to the given query, from a large corpus of untrimmed videos. As the moment referred to by the query is typically a small part of a video, we argue that the query is partially relevant to the video. It is worth pointing out that PRVR is different from conventional T2VR retrieval, where videos used for PRVR are much longer than that for T2VR.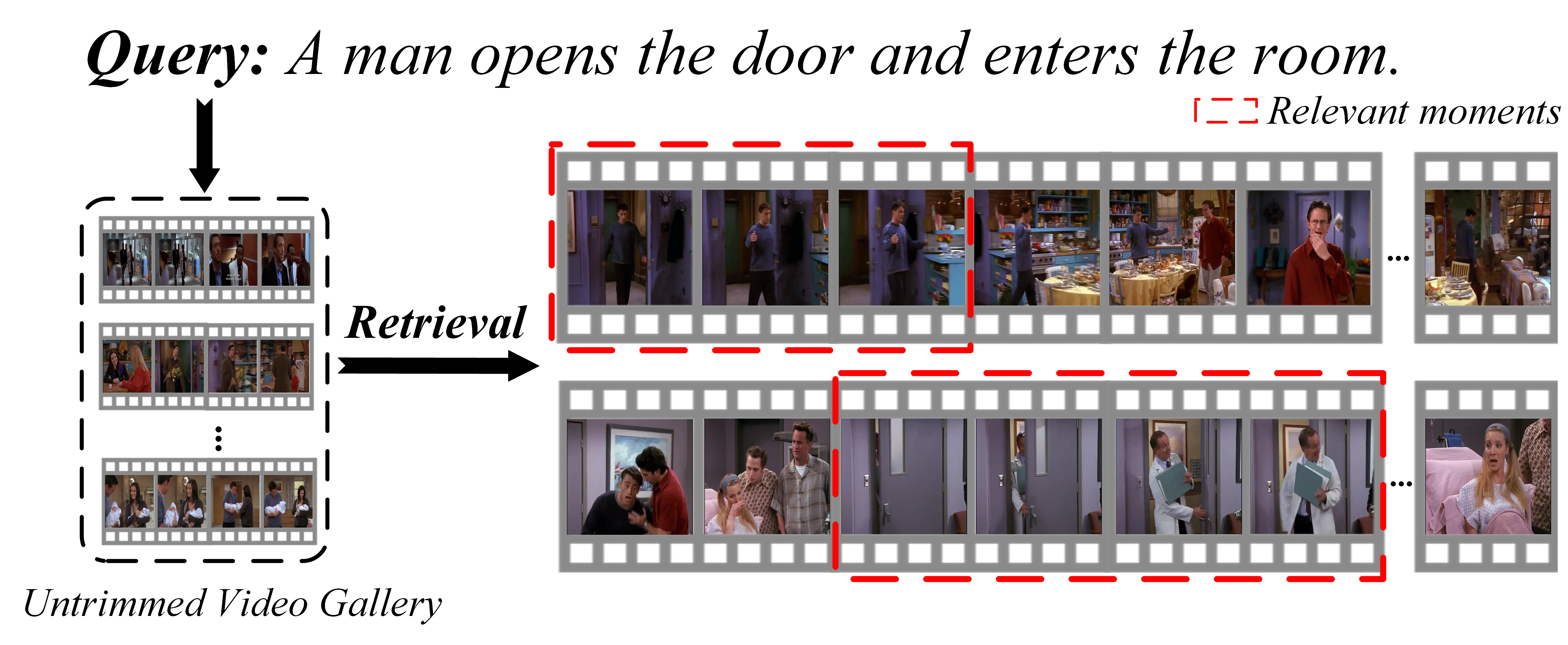
Benchmarks
These leaderboards are used to track progress in Partially Relevant Video Retrieval| Dataset | Best Model | Paper | Code | Compare |
|---|---|---|---|---|
| TV show Retrieval | DL-DKD | TVR: A Large-Scale Dataset for Video-Subtitle Moment Retrieval |  |
|
| Activitynet Captions | DL-DKD | Dynamic Temporal Pyramid Network: A Closer Look at Multi-Scale Modeling for Activity Detection | |
|
| Charades-STA | MS-SL | TALL: Temporal Activity Localization via Language Query | |
Performance Comparison
On TV show Retrieval:
| Model | R@1 | R@5 | R@10 | R@100 | SumR | ||||
|---|---|---|---|---|---|---|---|---|---|
| T2VR models: | |||||||||
| W2VV, TMM18 [1] | 2.6 | 5.6 | 7.5 | 20.6 | 36.3 | ||||
| HGR, CVPR20 [2] | 1.7 | 4.9 | 8.3 | 35.2 | 50.1 | ||||
| HTM, ICCV19 [3] | 3.8 | 12.0 | 19.1 | 63.2 | 98.2 | ||||
| CE, BMVC19 [4] | 3.7 | 12.8 | 20.1 | 64.5 | 101.1 | ||||
| W2VV++, MM19 [5] | 5.0 | 14.7 | 21.7 | 61.8 | 103.2 | ||||
| VSE++, BMVC19 [6] | 7.5 | 19.9 | 27.7 | 66.0 | 121.1 | ||||
| DE, CVPR19 [7] | 7.6 | 20.1 | 28.1 | 67.6 | 123.4 | ||||
| DE++, TPAMI21 [8] | 8.8 | 21.9 | 30.2 | 67.4 | 128.3 | ||||
| RIVRL, TCSVT22 [9] | 9.4 | 23.4 | 32.2 | 70.6 | 135.6 | ||||
| VCMR models w/o moment localization: | |||||||||
| XML, ECCV20 [10] | 10.0 | 26.5 | 37.3 | 81.3 | 155.1 | ||||
| ReLoCLNet, SIGIR21 [11] | 10.7 | 28.1 | 38.1 | 80.3 | 157.1 | ||||
| MS-SL | 13.5 | 32.1 | 43.4 | 83.4 | 172.3 | ||||
| DL-DKD | 14.4 | 34.9 | 45.8 | 84.9 | 179.9 | ||||
On Activitynet Captions:
| Model | R@1 | R@5 | R@10 | R@100 | SumR | ||||
|---|---|---|---|---|---|---|---|---|---|
| T2VR models: | |||||||||
| W2VV [1] | 2.2 | 9.5 | 16.6 | 45.5 | 73.8 | ||||
| HTM [3] | 3.7 | 13.7 | 22.3 | 66.2 | 105.9 | ||||
| HGR [2] | 4.0 | 15.0 | 24.8 | 63.2 | 107.0 | ||||
| RIVRL [9] | 5.2 | 18.0 | 28.2 | 66.4 | 117.8 | ||||
| VSE++ [6] | 4.9 | 17.7 | 28.2 | 67.1 | 117.9 | ||||
| DE++ [8] | 5.3 | 18.4 | 29.2 | 68.0 | 121.0 | ||||
| DE [7] | 5.6 | 18.8 | 29.4 | 67.8 | 121.7 | ||||
| W2VV++ [5] | 5.4 | 18.7 | 29.7 | 68.8 | 122.6 | ||||
| CE [4] | 5.5 | 19.1 | 29.9 | 71.1 | 125.6 | ||||
| VCMR models w/o moment localization: | |||||||||
| XML [10] | 5.7 | 18.9 | 30.0 | 72.0 | 126.6 | ||||
| ReLoCLNet [11] | 5.3 | 19.4 | 30.6 | 73.1 | 128.4 | ||||
| MS-SL | 7.1 | 22.5 | 34.7 | 75.8 | 140.1 | ||||
| DL-DKD | 8.0 | 25.0 | 37.5 | 77.1 | 147.6 | ||||
On Charades-STA:
| Model | R@1 | R@5 | R@10 | R@100 | SumR | ||||
|---|---|---|---|---|---|---|---|---|---|
| T2VR models: | |||||||||
| W2VV [1] | 0.5 | 2.9 | 4.7 | 24.5 | 32.6 | ||||
| VSE++ [6] | 0.8 | 3.9 | 7.2 | 31.7 | 43.6 | ||||
| W2VV++ [5] | 0.9 | 3.5 | 6.6 | 34.3 | 45.3 | ||||
| HGR [2] | 1.2 | 3.8 | 7.3 | 33.4 | 45.7 | ||||
| CE [4] | 1.3 | 4.5 | 7.3 | 36.0 | 49.1 | ||||
| DE [7] | 1.5 | 5.7 | 9.5 | 36.9 | 53.7 | ||||
| DE++ [8] | 1.7 | 5.6 | 9.6 | 37.1 | 54.1 | ||||
| RIVRL [9] | 1.6 | 5.6 | 9.4 | 37.7 | 54.3 | ||||
| HTM [3] | 1.2 | 5.4 | 9.2 | 44.2 | 60.0 | ||||
| VCMR models w/o moment localization: | |||||||||
| XML [10] | 1.2 | 5.4 | 10.0 | 45.6 | 62.3 | ||||
| ReLoCLNet [11] | 1.6 | 6.0 | 10.1 | 46.9 | 64.6 | ||||
| MS-SL | 1.8 | 7.1 | 11.8 | 47.7 | 68.4 | ||||
Methods
| Model | Paper | Code | Year |
|---|---|---|---|
| DL-DKD | Dual Learning with Dynamic Knowledge Distillation for Partially Relevant Video Retrieval | |
2023 |
| MS-SL | Partially Relevant Video Retrieval | |
2022 |
Reference
- Jianfeng Dong, Xirong Li, and Cees GM Snoek. 2018. Predicting visual features from text for image and video caption retrieval. IEEE Transactions on Multimedia. 20, 12 (2018), 3377–3388.
- Shizhe Chen, Yida Zhao, Qin Jin, and Qi Wu. 2020. Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10638–10647.
- Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. 2019. HowTo100M: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 2630–2640.
- Yang Liu, Samuel Albanie, Arsha Nagrani, and Andrew Zisserman. 2019. Use what you have: Video retrieval using representations from collaborative experts. arXiv preprint arXiv:1907.13487 (2019).
- Xirong Li, Chaoxi Xu, Gang Yang, Zhineng Chen, and Jianfeng Dong. 2019. W2VV++: Fully deep learning for ad-hoc video search. In Proceedings of the 27th ACM International Conference on Multimedia. 1786–1794.
- Fartash Faghri, David J Fleet, Jamie Ryan Kiros, and Sanja Fidler. 2018. VSE++: Improving visual-semantic embeddings with hard negatives. In Proceedings of the British Machine Vision Conference. 935–943.
- Jianfeng Dong, Xirong Li, Chaoxi Xu, Shouling Ji, Yuan He, Gang Yang, and Xun Wang. 2019. Dual encoding for zero-example video retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 9346–9355.
- Jianfeng Dong, Xirong Li, Chaoxi Xu, Xun Yang, Gang Yang, Xun Wang, and Meng Wang. 2021. Dual encoding for video retrieval by text. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021), 1-1.
- Jianfeng Dong, Yabing Wang, Xianke Chen, Xiaoye Qu, Xirong Li, Yuan He, and Xun Wang. 2022. Reading-strategy Inspired Visual Representation Learning for Text-to-Video Retrieval. IEEE Transactions on Circuits and Systems for Video Technology (2022).
- Jie Lei, Licheng Yu, Tamara L Berg, and Mohit Bansal. 2020. TVR: A large-scale dataset for video-subtitle moment retrieval. In European Conference on Computer Vision. 447–463.
- Hao Zhang, Aixin Sun, Wei Jing, Guoshun Nan, Liangli Zhen, Joey Tianyi Zhou, and Rick Siow Mong Goh. 2021. Video corpus moment retrieval with contrastive learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 685–695.